

26 aug.
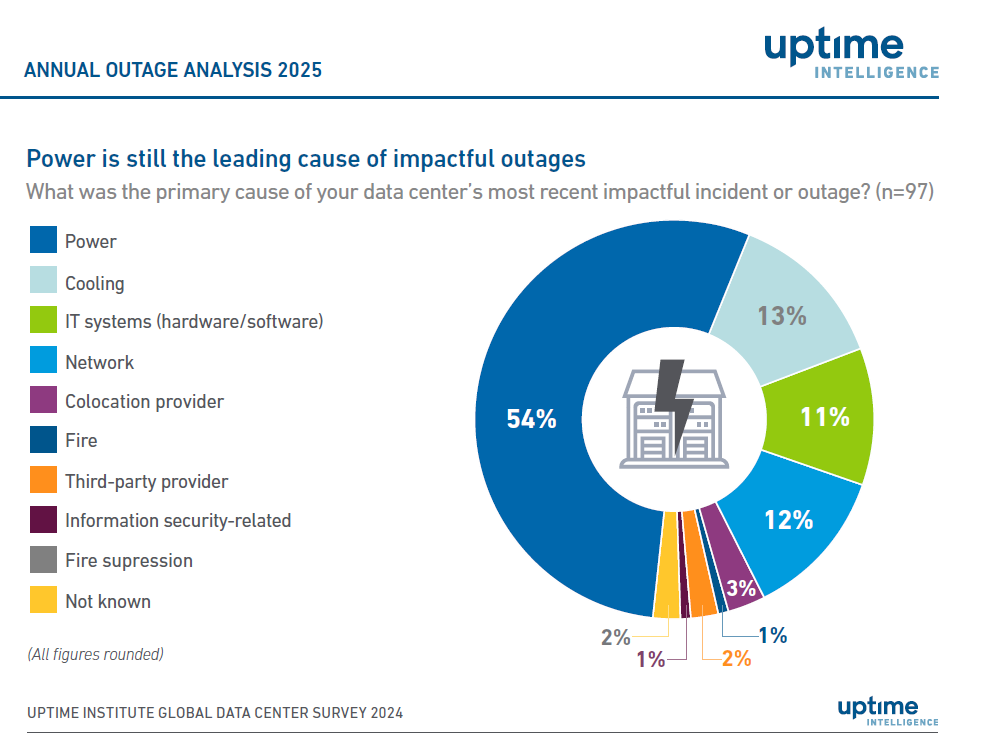
Raportul „Annual Outage Analysis 2025” realizat de Uptime Institute arată că industria DataCenter se confruntă cu un paradox. Deși frecvența generală a întreruperilor și nivelul de gravitate raportat scad pentru al patrulea an consecutiv, impactul financiar și reputațional al acestora devine tot mai grav. În 2024, mai bine de jumătate (54%) dintre organizațiile chestionate au declarat că ultima lor întrerupere/defecțiune serioasă a depășit pragul de 100.000 de dolari, iar una din cinci a raportat pierderi de peste 1 milion de dolari.
Cum au arătat cu adevărat ultimii ani pentru operatorii de centre de date când vine vorba de întreruperi operaționale? Dincolo de grafice și statistici, fiecare procent ascunde povești reale – incidente mediatizate și pierderi financiare majore, care demonstrează cât de fragil poate fi echilibrul între disponibilitate și blocaj.
Energia, „călcâiul lui Ahile” în industria data center
Chiar dacă doar 9% dintre incidentele raportate în 2024 au fost încadrate ca fiind serioase sau severe – cel mai mic nivel consemnat vreodată de Uptime – energia rămâne „călcâiul lui Ahile” în centrele de date, generând peste jumătate (54%) dintre întreruperile cu impact major. Cifrele devin și mai relevante când le punem lângă cazuri reale – să analizăm câteva exemple concrete.
În octombrie 2023, o defecțiune a sistemului de distribuție electrică dintr-un centru de date Microsoft din Olanda a provocat o întrerupere de aproape două ore, după ce trecerea de la rețeaua publică către generatoarele de rezervă a eșuat parțial. Incidentul a afectat servicii esențiale Azure – de la App Service și SQL DB la stocare și mașini virtuale – iar aproximativ 1% din rackuri au rămas fără curent. Recuperarea completă a durat până la orele serii, unele conturi de stocare fiind afectate mai multe ore, cu impact direct asupra clienților și serviciilor critice dependente de acestea. Microsoft nu a făcut publice detaliile despre impactul financiar al acestei întreruperi.
Facilitățile de răcire, rețeaua și IT-ul – următorii mari factori de risc
Raportul Uptime Institute arată și că, în spatele energiei, vin din urmă sistemele de răcire (13%), rețeaua (12%) și sistemele IT (11%), confirmând că infrastructura critică rămâne vulnerabilă tocmai în punctele unde ar trebui să fie cea mai puternică.
Știm deja, canicula nu e cel mai bun prieten al operatorilor data center. Să ne amintim cum, în iulie 2022, centrele de date din Londra ale Google și Oracle au fost afectate de o val de căldură record, cu temperaturi de peste 40 °C, care a provocat probleme la sistemele de răcire. Primul anunț la Oracle despre incident menționa că „temperaturile nerezonabile” au afectat echipamentele cloud și de rețea din centrul său din sudul Londrei, generând întreruperi pe durata zilei și impactând clienții. La rândul său, ca măsură de protecție, Google a oprit parțial serviciile cloud pentru câteva ore, pentru a preveni deteriorarea echipamentelor și întreruperi prelungite, afectând un număr mic de utilizatori și provocând indisponibilitate temporară pentru servicii precum web-hostingul WordPress în Europa.

Un incident mai puțin obișnuit a fost povestit recent de către Rick Bentley, fondatorul companiilor Cloudastructure și Hydro Hash, care deține un centru de date de tip crypto mining alimentat cu energie hidro. Acesta a avut loc în Montana, SUA, unde centrul de date „a înghețat complet peste noapte”. Aici problema a fost, din contră, scăderea rapidă a temperaturii de la -6°C la -34°C în mai puțin de 24 de ore. Bentley a subliniat că, deși echipa credea că este pregătită, combinarea frigului extrem cu o pană de curent a făcut incidentul inevitabil.
Infrastructurile IT complexe înseamnă întreruperi mai frecvente
Spuneam mai sus că, în 2024, aproape un sfert dintre întreruperile cu impact major au fost cauzate de probleme IT și de rețea – o tendință explicabilă prin complexitatea tot mai mare a infrastructurilor și riscurile asociate configurărilor incorecte. Datele Uptime Institute confirmă: cele mai frecvente cauze ale întreruperilor legate de serviciile IT sunt problemele de rețea și conectivitate (30%), sistemele IT și software-ul (23%), întreruperile de curent (18%), serviciile IT terțe, cum ar fi cloud public sau SaaS (8%), și problemele de răcire (7%).
Un caz reprezentativ este incidentul din 20 iulie 2025, care a avut in prim-plan Alaska Airlines. Acesta ilustrează faptul că daunele majore nu sunt doar financiare, ci și de reputație. Compania aeriană din SUA a suferit o defecțiune critică la nivel de hardware în centrele sale de date, ceea ce a dus la suspendarea tuturor zborurilor timp de aproximativ trei ore, între orele 20:00 și 23:00 PT. Problema a afectat operațiunile principale de zbor și a avut repercusiuni și asupra filialei Horizon Air. Ca urmare, pe 21 iulie, datele FlightAware arătau că 7% din zboruri (66) au fost anulate, iar alte 12% (110) au înregistrat întârzieri, ceea ce a dus la aglomerarea aeroporturilor și confuzie în rândul pasagerilor. Defecțiunea hardware ar fi fost produsă de o componentă furnizată de terți, compania precizând că lucrează împreună cu acest furnizor pentru a remedia problema.
Întreruperile operaționale cauzate de erori umane, în creștere
În 2025, întreruperile cauzate de erori umane au crescut, cu 10 puncte procentuale față de 2024, cauza cea mai frecventă fiind nerespectarea procedurilor, posibil amplificată de creșterea rapidă a industriei și lipsa de personal. Investițiile în instruirea angajaților și suportul operațional în timp real pot reduce riscurile. Uptime Institute arată că, în ultimii trei ani, principalele cauze ale erorilor umane majore au fost, pe lângă nerespectarea procedurilor (58%), și procesele greșite urmate de personal (45%), lipsa personalului (18%), mentenanță preventivă insuficientă (16%) și omisiuni în proiectarea centrului de date (14%).
În loc de concluzie
Pe măsură ce infrastructura data center devine tot mai complexă și interconectată, riscurile operaționale se diversifică și sunt mai costisitoare. Chiar și infrastructura proiectată să fie robustă poate fi vulnerabilă la condiții extreme sau la erori de configurare, ceea ce subliniază importanța unei strategii integrate de prevenție.
Pentru a reduce riscul de întreruperi în centrele de date, sunt esențiale mai multe măsuri complementare: sisteme redundante de alimentare (generatoare și UPS-uri) pentru funcționarea fără întreruperi a hardware-ului; întreținere și testare regulată, sprijinite de monitorizare și analiză predictivă; failover către site-uri mirror pentru redirecționarea rapidă a traficului; planuri de recuperare în caz de dezastru cu checklist-uri și exerciții periodice, dar și instruirea personalului pentru reducerea erorilor umane.




